NeurIPS 2025 Spotlight | 你刷到的视频是真的么?用物理规律拆穿Sora谎言
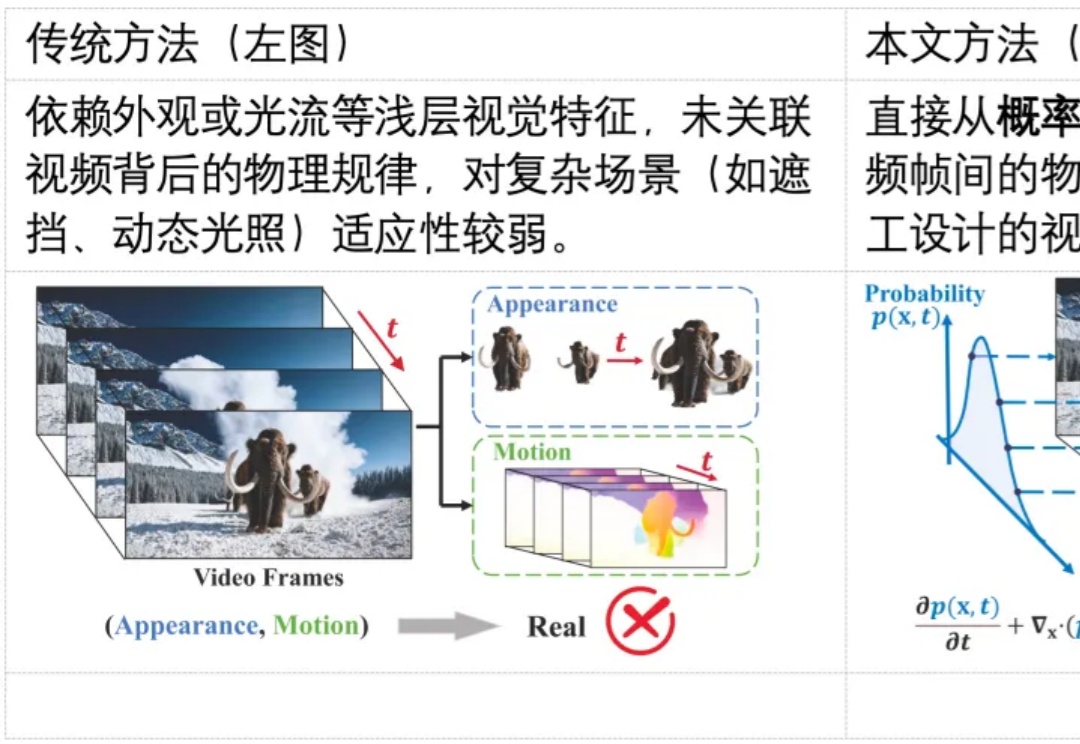
NeurIPS 2025 Spotlight | 你刷到的视频是真的么?用物理规律拆穿Sora谎言随着生成式 AI(如 Sora)的发展,合成视频几乎可以以假乱真,带来了深度伪造与虚假信息传播的风险。现有检测方法多依赖表层伪影或数据驱动学习,难以在高质量生成视频中保持较好的泛化能力。其根本原因在于,这些方法大都未能充分利用自然视频所遵循的物理规律,挖掘自然视频的更本质的特征。
来自主题: AI技术研报
9881 点击 2025-11-06 09:39